



Fascinating Deepseek Techniques That May help Your small business Grow
페이지 정보

본문
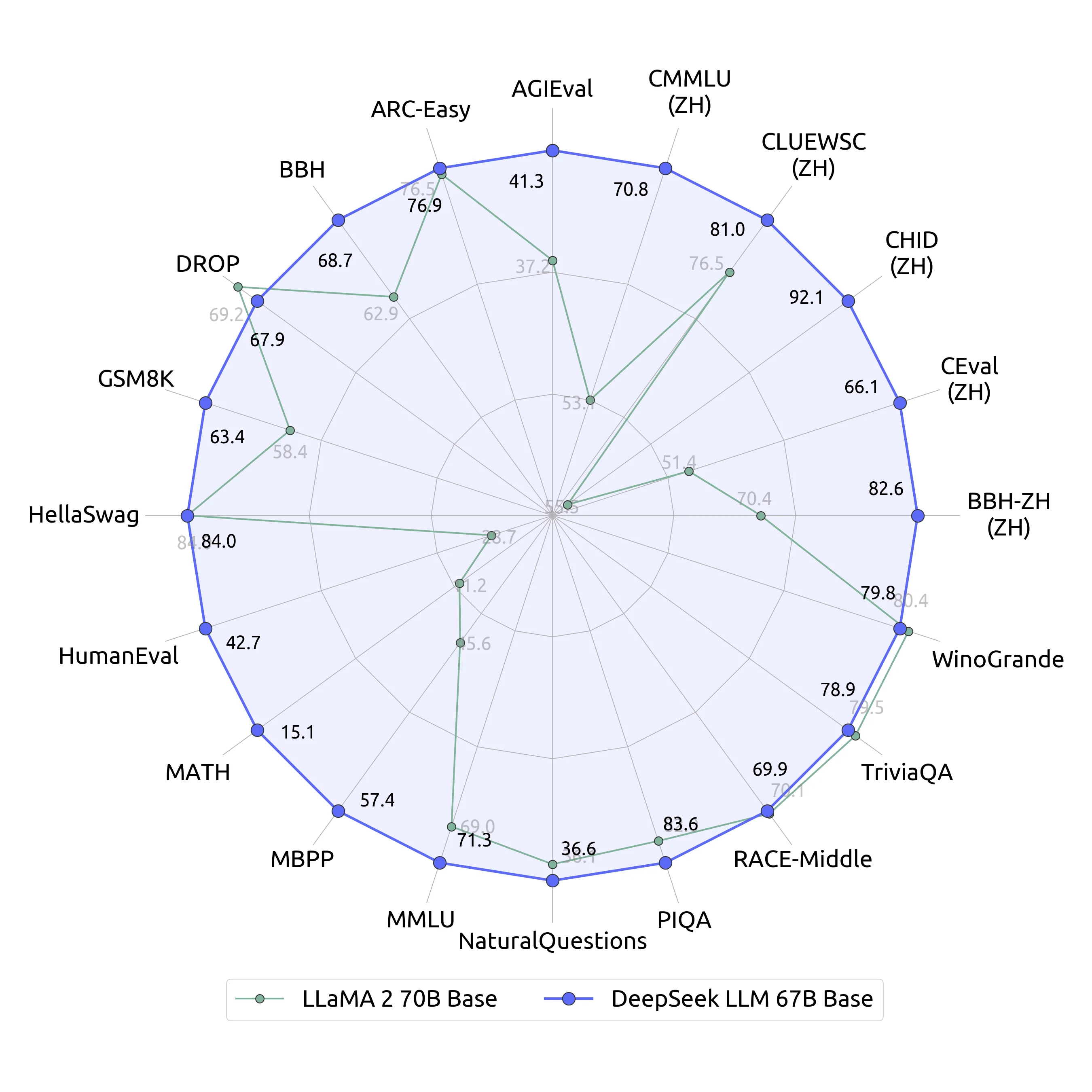 To ensure a fair assessment of DeepSeek LLM 67B Chat, the developers introduced contemporary drawback units. Although LLMs will help builders to be more productive, prior empirical research have proven that LLMs can generate insecure code. The model can ask the robots to carry out duties and they use onboard programs and software (e.g, local cameras and object detectors and movement policies) to help them do that. If your system does not have quite enough RAM to fully load the mannequin at startup, you possibly can create a swap file to assist with the loading. Parse Dependency between recordsdata, then arrange information in order that ensures context of each file is before the code of the present file. I also assume the low precision of higher dimensions lowers the compute price so it's comparable to current models. For Budget Constraints: If you're limited by funds, concentrate on Deepseek GGML/GGUF models that match within the sytem RAM.
To ensure a fair assessment of DeepSeek LLM 67B Chat, the developers introduced contemporary drawback units. Although LLMs will help builders to be more productive, prior empirical research have proven that LLMs can generate insecure code. The model can ask the robots to carry out duties and they use onboard programs and software (e.g, local cameras and object detectors and movement policies) to help them do that. If your system does not have quite enough RAM to fully load the mannequin at startup, you possibly can create a swap file to assist with the loading. Parse Dependency between recordsdata, then arrange information in order that ensures context of each file is before the code of the present file. I also assume the low precision of higher dimensions lowers the compute price so it's comparable to current models. For Budget Constraints: If you're limited by funds, concentrate on Deepseek GGML/GGUF models that match within the sytem RAM.
The DDR5-6400 RAM can provide up to 100 GB/s. 1. Over-reliance on coaching data: These models are trained on vast quantities of text information, which can introduce biases current in the information. There are also agreements referring to overseas intelligence and criminal enforcement entry, including data sharing treaties with ‘Five Eyes’, in addition to Interpol. 1 and DeepSeek-R1 exhibit a step operate in model intelligence. DeepSeek-R1-Distill fashions are wonderful-tuned primarily based on open-supply models, utilizing samples generated by DeepSeek-R1. DeepSeek-R1. Released in January 2025, this mannequin is based on DeepSeek-V3 and is targeted on superior reasoning duties instantly competing with OpenAI's o1 model in performance, whereas sustaining a considerably decrease cost structure. As we funnel all the way down to decrease dimensions, we’re primarily performing a realized type of dimensionality discount that preserves probably the most promising reasoning pathways while discarding irrelevant directions. As reasoning progresses, we’d undertaking into more and more centered areas with increased precision per dimension. What if, as an alternative of treating all reasoning steps uniformly, we designed the latent space to mirror ديب سيك how advanced drawback-fixing naturally progresses-from broad exploration to precise refinement? An experimental exploration reveals that incorporating multi-selection (MC) questions from Chinese exams considerably enhances benchmark efficiency. Consider also the form of the exploration term.
I discover the chat to be almost ineffective. Furthermore, open-ended evaluations reveal that DeepSeek LLM 67B Chat exhibits superior efficiency in comparison with GPT-3.5. Information included DeepSeek chat historical past, back-end knowledge, log streams, API keys and operational particulars. It’s significantly extra environment friendly than other models in its class, will get nice scores, and the analysis paper has a bunch of details that tells us that DeepSeek has constructed a staff that deeply understands the infrastructure required to prepare ambitious fashions. The development team at Sourcegraph, declare that Cody is " the only AI coding assistant that knows your complete codebase." Cody answers technical questions and writes code immediately in your IDE, utilizing your code graph for context and accuracy. By crawling knowledge from LeetCode, the analysis metric aligns with HumanEval standards, demonstrating the model’s efficacy in solving real-world coding challenges. A number of notes on the very newest, new models outperforming GPT models at coding. We comply with the scoring metric in the answer.pdf to evaluate all fashions. If you are venturing into the realm of larger fashions the hardware necessities shift noticeably. If the 7B mannequin is what you're after, you gotta think about hardware in two ways. The performance of an Deepseek model depends heavily on the hardware it is running on.
When operating Deepseek AI models, you gotta concentrate to how RAM bandwidth and mdodel dimension affect inference pace. The eye is All You Need paper introduced multi-head attention, which will be thought of as: "multi-head attention permits the mannequin to jointly attend to info from totally different representation subspaces at completely different positions. DeepSeek-R1-Lite-Preview exhibits regular rating improvements on AIME as thought size will increase. ???? Transparent thought course of in actual-time. We structure the latent reasoning space as a progressive funnel: beginning with high-dimensional, low-precision representations that gradually remodel into lower-dimensional, high-precision ones. This suggests structuring the latent reasoning house as a progressive funnel: beginning with excessive-dimensional, low-precision representations that step by step remodel into decrease-dimensional, high-precision ones. I have been thinking in regards to the geometric structure of the latent house the place this reasoning can occur. I wish to propose a distinct geometric perspective on how we construction the latent reasoning space. The downside, and the rationale why I do not list that because the default choice, is that the files are then hidden away in a cache folder and it is harder to know the place your disk space is getting used, and to clear it up if/when you need to take away a download mannequin.
If you beloved this article and you simply would like to receive more info pertaining to ديب سيك مجانا kindly visit our own web site.
- 이전글10 Things That Your Family Taught You About Best Budget Robot Vacuum 25.02.03
- 다음글Patio Door Lock Repair Near Me Tools To Help You Manage Your Everyday Lifethe Only Patio Door Lock Repair Near Me Trick That Everyone Should Be Able To 25.02.03
댓글목록
등록된 댓글이 없습니다.