



Tips on how to Make Your Deepseek Look Superb In 5 Days
페이지 정보

본문
 This does not account for other initiatives they used as ingredients for DeepSeek V3, equivalent to DeepSeek r1 lite, which was used for artificial knowledge. The chance of these projects going incorrect decreases as extra individuals gain the knowledge to do so. So whereas diverse coaching datasets enhance LLMs’ capabilities, in addition they enhance the danger of generating what Beijing views as unacceptable output. A second level to contemplate is why DeepSeek is coaching on solely 2048 GPUs whereas Meta highlights coaching their model on a larger than 16K GPU cluster. The analysis highlights how rapidly reinforcement studying is maturing as a subject (recall how in 2013 the most impressive thing RL might do was play Space Invaders). Jordan Schneider: Alessio, I want to come back again to one of many stuff you said about this breakdown between having these research researchers and the engineers who are more on the system facet doing the actual implementation.
This does not account for other initiatives they used as ingredients for DeepSeek V3, equivalent to DeepSeek r1 lite, which was used for artificial knowledge. The chance of these projects going incorrect decreases as extra individuals gain the knowledge to do so. So whereas diverse coaching datasets enhance LLMs’ capabilities, in addition they enhance the danger of generating what Beijing views as unacceptable output. A second level to contemplate is why DeepSeek is coaching on solely 2048 GPUs whereas Meta highlights coaching their model on a larger than 16K GPU cluster. The analysis highlights how rapidly reinforcement studying is maturing as a subject (recall how in 2013 the most impressive thing RL might do was play Space Invaders). Jordan Schneider: Alessio, I want to come back again to one of many stuff you said about this breakdown between having these research researchers and the engineers who are more on the system facet doing the actual implementation.
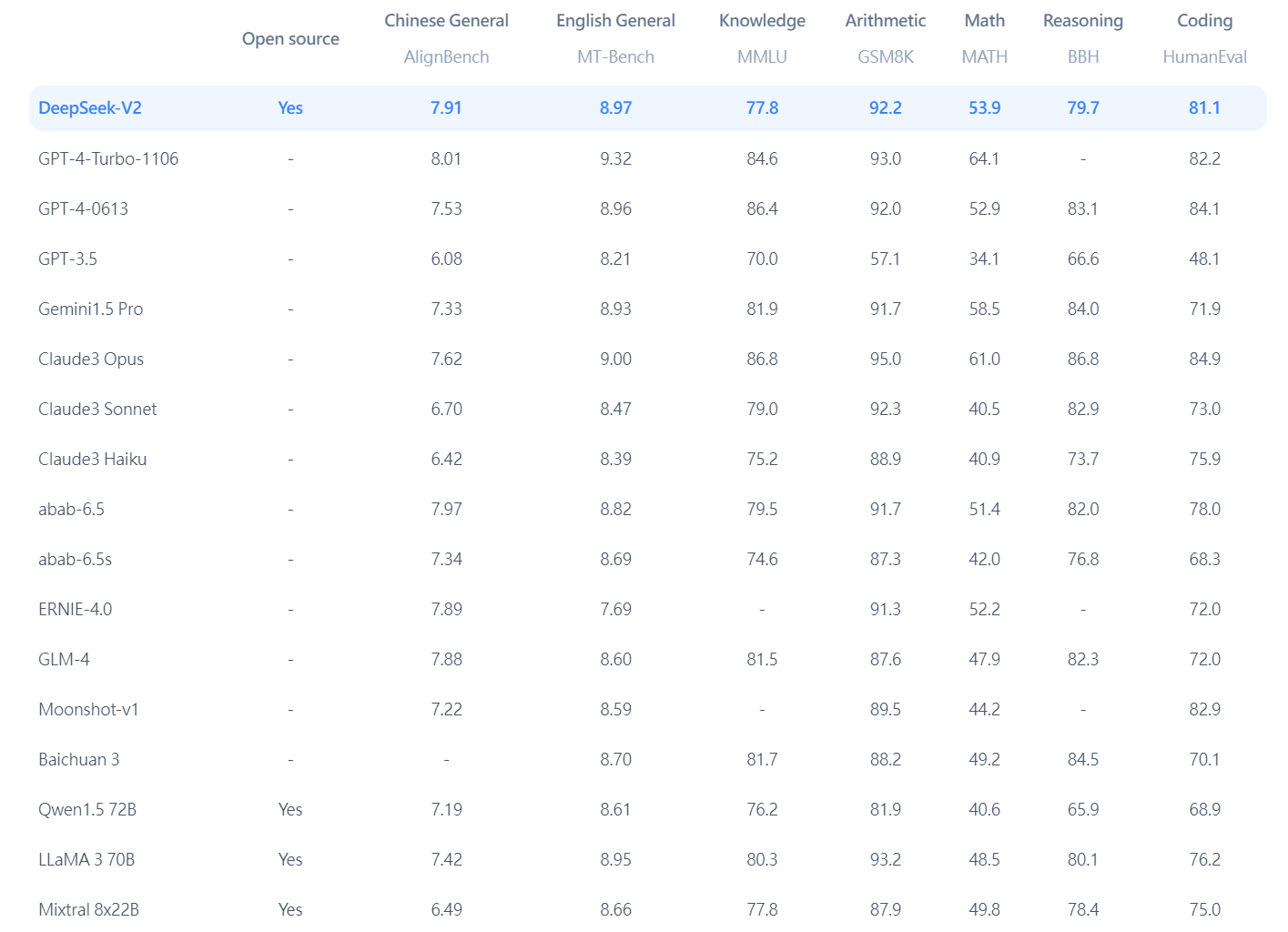 Note that the aforementioned costs embody only the official coaching of DeepSeek-V3, excluding the prices associated with prior analysis and ablation experiments on architectures, algorithms, or information. The overall compute used for the DeepSeek V3 model for pretraining experiments would probably be 2-four times the reported quantity in the paper. Custom multi-GPU communication protocols to make up for the slower communication speed of the H800 and optimize pretraining throughput. Tracking the compute used for a mission simply off the ultimate pretraining run is a very unhelpful method to estimate actual value. It’s a really helpful measure for understanding the actual utilization of the compute and the efficiency of the underlying studying, but assigning a price to the model based in the marketplace value for the GPUs used for the final run is deceptive. The technical report shares numerous details on modeling and infrastructure choices that dictated the final end result. The price of progress in AI is far closer to this, at the very least till substantial enhancements are made to the open variations of infrastructure (code and data7).
Note that the aforementioned costs embody only the official coaching of DeepSeek-V3, excluding the prices associated with prior analysis and ablation experiments on architectures, algorithms, or information. The overall compute used for the DeepSeek V3 model for pretraining experiments would probably be 2-four times the reported quantity in the paper. Custom multi-GPU communication protocols to make up for the slower communication speed of the H800 and optimize pretraining throughput. Tracking the compute used for a mission simply off the ultimate pretraining run is a very unhelpful method to estimate actual value. It’s a really helpful measure for understanding the actual utilization of the compute and the efficiency of the underlying studying, but assigning a price to the model based in the marketplace value for the GPUs used for the final run is deceptive. The technical report shares numerous details on modeling and infrastructure choices that dictated the final end result. The price of progress in AI is far closer to this, at the very least till substantial enhancements are made to the open variations of infrastructure (code and data7).
That is the uncooked measure of infrastructure efficiency. That is comparing efficiency. We’ll get into the precise numbers beneath, however the question is, which of the many technical improvements listed in the DeepSeek V3 report contributed most to its studying efficiency - i.e. mannequin efficiency relative to compute used. All bells and whistles aside, the deliverable that matters is how good the models are relative to FLOPs spent. The technique to interpret both discussions should be grounded in the truth that the DeepSeek V3 model is extremely good on a per-FLOP comparison to peer models (probably even some closed API fashions, extra on this under). For Chinese companies which are feeling the stress of substantial chip export controls, it can't be seen as notably surprising to have the angle be "Wow we are able to do way greater than you with less." I’d most likely do the same of their footwear, it is much more motivating than "my cluster is greater than yours." This goes to say that we'd like to grasp how vital the narrative of compute numbers is to their reporting. To translate - they’re nonetheless very sturdy GPUs, however prohibit the effective configurations you should utilize them in. If layers are offloaded to the GPU, this can cut back RAM usage and use VRAM instead.
How a lot RAM do we'd like? The cumulative query of how a lot total compute is utilized in experimentation for a mannequin like this is much trickier. This seems like 1000s of runs at a very small size, doubtless 1B-7B, to intermediate knowledge quantities (anyplace from Chinchilla optimum to 1T tokens). Another surprising thing is that free deepseek small fashions typically outperform varied larger models. The sad thing is as time passes we know much less and fewer about what the large labs are doing because they don’t inform us, at all. A real price of possession of the GPUs - to be clear, we don’t know if free deepseek owns or rents the GPUs - would comply with an analysis similar to the SemiAnalysis total price of ownership model (paid characteristic on top of the newsletter) that incorporates costs in addition to the actual GPUs. Ed. Don’t miss Nancy’s excellent rundown on this distinction! Alibaba’s Qwen mannequin is the world’s best open weight code mannequin (Import AI 392) - and they achieved this by means of a mix of algorithmic insights and access to information (5.5 trillion prime quality code/math ones).
If you're ready to check out more info regarding ديب سيك look at our web-site.
- 이전글Who Is Locksmith Automotive Near Me And Why You Should Care 25.02.01
- 다음글Need Inspiration? Look Up Symptoms Of Adult ADD 25.02.01
댓글목록
등록된 댓글이 없습니다.