



Details Of Deepseek
페이지 정보

본문
 For instance, many people say that Deepseek R1 can compete with-and even beat-other top AI fashions like OpenAI’s O1 and ChatGPT. DeepSeek, too, is working towards constructing capabilities for using ChatGPT effectively within the software improvement sector, while simultaneously attempting to get rid of hallucinations and rectify logical inconsistencies in code generation. На самом деле эту модель можно с успехом и хорошими результатами использовать в задачах по извлечению дополненной информации (Retrieval Augmented Generation). We additionally strive to supply researchers with more instruments and concepts to make sure that in end result the developer tooling evolves further in the applying of ML to code technology and software program improvement generally. The aim of this put up is to Deep seek-dive into LLM’s which might be specialised in code generation tasks, and see if we can use them to jot down code. The DeepSeek-R1 model incorporates "chain-of-thought" reasoning, permitting it to excel in complex duties, notably in arithmetic and coding. Hermes three is a generalist language mannequin with many improvements over Hermes 2, together with advanced agentic capabilities, a lot better roleplaying, reasoning, multi-turn dialog, long context coherence, and enhancements throughout the board. First, the policy is a language model that takes in a prompt and returns a sequence of text (or just probability distributions over textual content).
For instance, many people say that Deepseek R1 can compete with-and even beat-other top AI fashions like OpenAI’s O1 and ChatGPT. DeepSeek, too, is working towards constructing capabilities for using ChatGPT effectively within the software improvement sector, while simultaneously attempting to get rid of hallucinations and rectify logical inconsistencies in code generation. На самом деле эту модель можно с успехом и хорошими результатами использовать в задачах по извлечению дополненной информации (Retrieval Augmented Generation). We additionally strive to supply researchers with more instruments and concepts to make sure that in end result the developer tooling evolves further in the applying of ML to code technology and software program improvement generally. The aim of this put up is to Deep seek-dive into LLM’s which might be specialised in code generation tasks, and see if we can use them to jot down code. The DeepSeek-R1 model incorporates "chain-of-thought" reasoning, permitting it to excel in complex duties, notably in arithmetic and coding. Hermes three is a generalist language mannequin with many improvements over Hermes 2, together with advanced agentic capabilities, a lot better roleplaying, reasoning, multi-turn dialog, long context coherence, and enhancements throughout the board. First, the policy is a language model that takes in a prompt and returns a sequence of text (or just probability distributions over textual content).
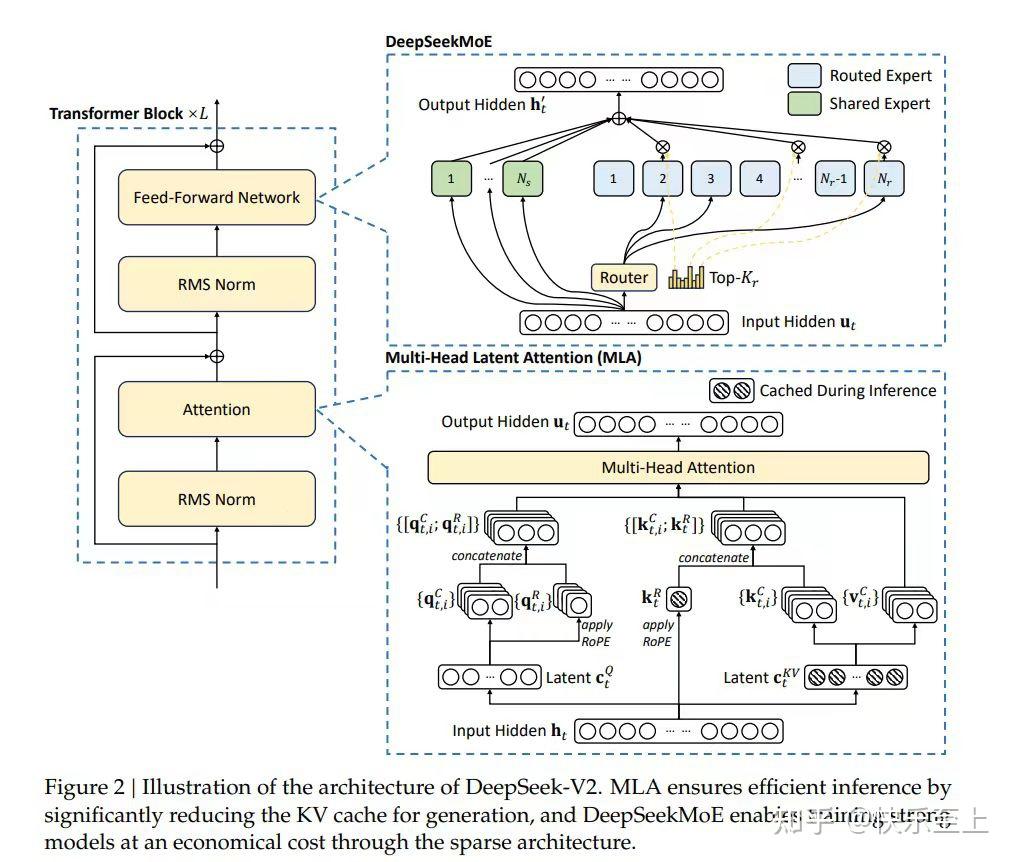 While inference-time explainability in language fashions remains to be in its infancy and would require important improvement to succeed in maturity, the baby steps we see in the present day could assist lead to future methods that safely and reliably assist people. DeepSeek AI Detector helps massive text inputs, but there may be an higher phrase restrict depending on the subscription plan you select. The KL divergence term penalizes the RL coverage from moving considerably away from the initial pretrained model with each coaching batch, which might be helpful to verify the model outputs moderately coherent text snippets. In addition, per-token probability distributions from the RL coverage are compared to the ones from the initial mannequin to compute a penalty on the difference between them. On the TruthfulQA benchmark, InstructGPT generates truthful and informative answers about twice as usually as GPT-three During RLHF fine-tuning, we observe performance regressions in comparison with GPT-three We are able to enormously scale back the performance regressions on these datasets by mixing PPO updates with updates that increase the log probability of the pretraining distribution (PPO-ptx), without compromising labeler choice scores. As well as, in contrast with DeepSeek-V2, the new pretokenizer introduces tokens that mix punctuations and line breaks. In addition, we add a per-token KL penalty from the SFT mannequin at every token to mitigate overoptimization of the reward mannequin.
While inference-time explainability in language fashions remains to be in its infancy and would require important improvement to succeed in maturity, the baby steps we see in the present day could assist lead to future methods that safely and reliably assist people. DeepSeek AI Detector helps massive text inputs, but there may be an higher phrase restrict depending on the subscription plan you select. The KL divergence term penalizes the RL coverage from moving considerably away from the initial pretrained model with each coaching batch, which might be helpful to verify the model outputs moderately coherent text snippets. In addition, per-token probability distributions from the RL coverage are compared to the ones from the initial mannequin to compute a penalty on the difference between them. On the TruthfulQA benchmark, InstructGPT generates truthful and informative answers about twice as usually as GPT-three During RLHF fine-tuning, we observe performance regressions in comparison with GPT-three We are able to enormously scale back the performance regressions on these datasets by mixing PPO updates with updates that increase the log probability of the pretraining distribution (PPO-ptx), without compromising labeler choice scores. As well as, in contrast with DeepSeek-V2, the new pretokenizer introduces tokens that mix punctuations and line breaks. In addition, we add a per-token KL penalty from the SFT mannequin at every token to mitigate overoptimization of the reward mannequin.
The key takeaway here is that we all the time want to give attention to new options that add the most value to DevQualityEval. ???? This pricing model considerably undercuts rivals, providing exceptional value for performance. 2. If it seems to be cheap to practice good LLMs, captured worth may shift back to frontier labs, and even to downstream applications. 8 Mac Minis, not even working Apple’s finest chips. Even if you are very AI-pilled, we nonetheless stay on this planet where market dynamics are much stronger than labour automation effects. Note that tokens exterior the sliding window nonetheless affect next word prediction. This ought to be interesting to any builders working in enterprises which have information privacy and sharing considerations, but nonetheless need to improve their developer productivity with domestically running fashions. Besides, we try to arrange the pretraining information at the repository stage to boost the pre-skilled model’s understanding capability throughout the context of cross-files within a repository They do this, by doing a topological kind on the dependent recordsdata and appending them into the context window of the LLM. First, we swapped our knowledge source to make use of the github-code-clean dataset, containing 115 million code information taken from GitHub. The Chinese engineers said they needed only about $6 million in uncooked computing power to construct their new system.
Most nations blocking DeepSeek programmes say they are involved about the security dangers posed by the Chinese software. Instead of simply passing in the current file, the dependent information inside repository are parsed. By aligning recordsdata primarily based on dependencies, it accurately represents actual coding practices and constructions. This also explains why Softbank (and no matter traders Masayoshi Son brings collectively) would supply the funding for OpenAI that Microsoft is not going to: the idea that we are reaching a takeoff level where there will in actual fact be actual returns towards being first. Each command serves a unique objective: The primary command installs Ollama; The second command starts the Ollama service; The third command verifies the installation by displaying the installed model. "Let’s first formulate this high quality-tuning job as a RL downside. DeepSeek online replaces supervised effective-tuning and RLHF with a reinforcement-studying step that is fully automated. Why instruction fantastic-tuning ? To guage the generalization capabilities of Mistral 7B, we high quality-tuned it on instruction datasets publicly obtainable on the Hugging Face repository. No proprietary data or coaching tips had been utilized: Mistral 7B - Instruct model is an easy and preliminary demonstration that the bottom model can easily be superb-tuned to achieve good performance. Use FP8 Precision: Maximize efficiency for both coaching and inference.
If you adored this information and you would like to receive even more info relating to Deep seek kindly see our page.
- 이전글Archie's Pub And Eatery In De Pere, Wi 25.03.22
- 다음글1M Kicks Off Partnership With TiE Chennai 25.03.22
댓글목록
등록된 댓글이 없습니다.