



Build A Deepseek Anyone Would be Proud of
페이지 정보

본문
Absolutely. The DeepSeek App is developed with high-notch safety protocols to ensure your information stays protected and non-public. Is DeepSeek Ai Chat AI safe? DeepSeek-R1, released by DeepSeek. Three above. Then final week, they launched "R1", which added a second stage. Anthropic, DeepSeek, and plenty of different corporations (maybe most notably OpenAI who released their o1-preview model in September) have discovered that this coaching tremendously will increase performance on sure select, objectively measurable duties like math, coding competitions, and on reasoning that resembles these tasks. 1. Scaling laws. A property of AI - which I and my co-founders were amongst the first to document back after we worked at OpenAI - is that every one else equal, scaling up the training of AI methods results in smoothly better outcomes on a range of cognitive tasks, throughout the board. Every occasionally, the underlying factor that is being scaled adjustments a bit, or a new sort of scaling is added to the training course of. Despite being the smallest mannequin with a capacity of 1.Three billion parameters, DeepSeek-Coder outperforms its larger counterparts, StarCoder and CodeLlama, in these benchmarks. It matches or outperforms Full Attention fashions on normal benchmarks, long-context tasks, and instruction-primarily based reasoning.
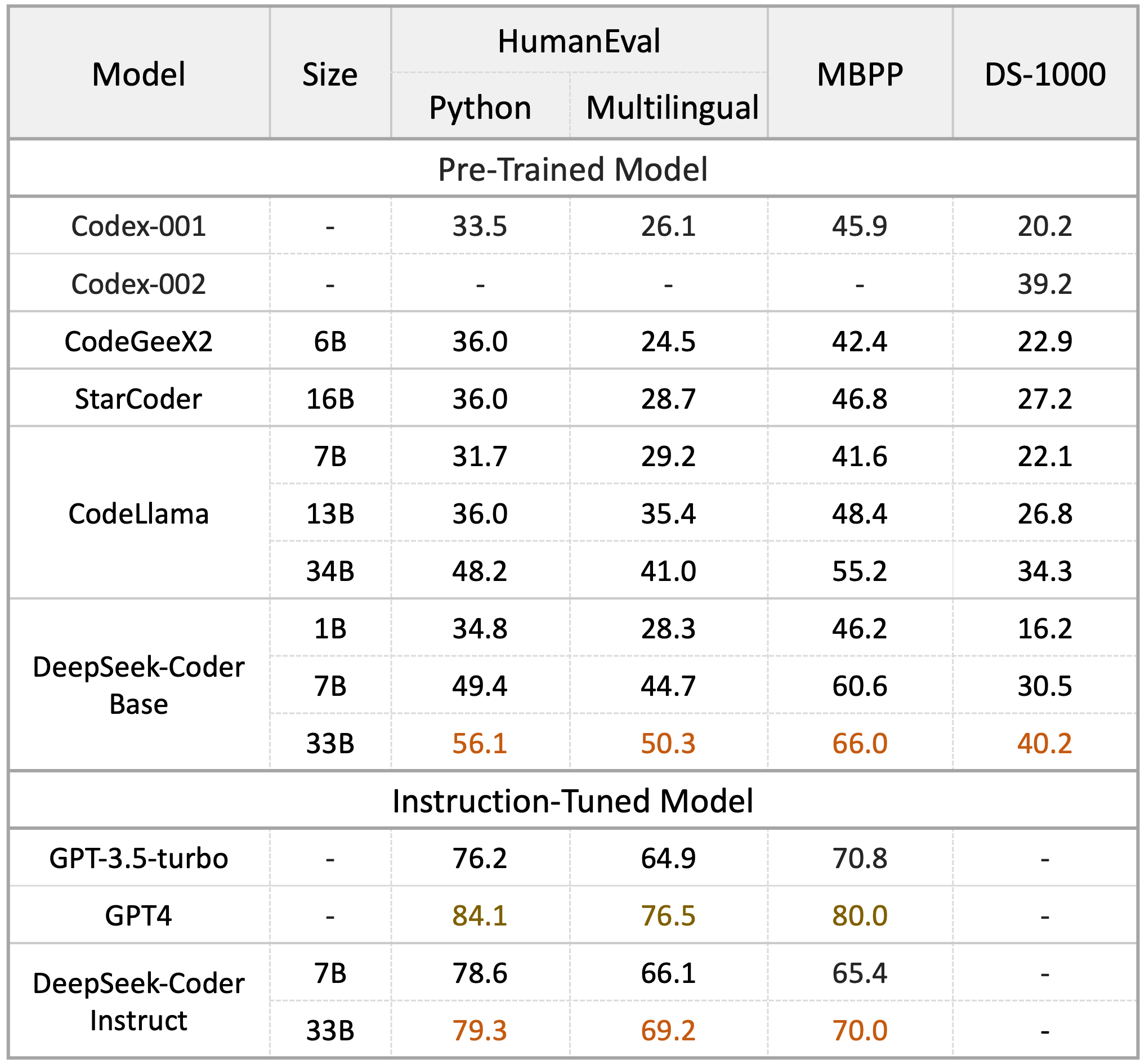 The outcome shows that DeepSeek-Coder-Base-33B significantly outperforms current open-supply code LLMs. Shifts within the coaching curve additionally shift the inference curve, and because of this giant decreases in value holding fixed the standard of mannequin have been occurring for years. The result is a "general-function robotic foundation mannequin that we name π0 (pi-zero)," they write. The arrogance on this statement is barely surpassed by the futility: right here we're six years later, and all the world has access to the weights of a dramatically superior mannequin. Thus, I believe a fair statement is "DeepSeek produced a mannequin near the efficiency of US fashions 7-10 months older, for a superb deal less cost (however not anywhere near the ratios folks have instructed)". But we should not hand the Chinese Communist Party technological benefits when we don't should. Given the United States’ comparative advantages in compute access and reducing-edge models, the incoming administration might discover the time to be right to cash in and put AI export globally at the heart of Trump’s tech policy. This new paradigm entails beginning with the unusual kind of pretrained models, after which as a second stage utilizing RL so as to add the reasoning skills.
The outcome shows that DeepSeek-Coder-Base-33B significantly outperforms current open-supply code LLMs. Shifts within the coaching curve additionally shift the inference curve, and because of this giant decreases in value holding fixed the standard of mannequin have been occurring for years. The result is a "general-function robotic foundation mannequin that we name π0 (pi-zero)," they write. The arrogance on this statement is barely surpassed by the futility: right here we're six years later, and all the world has access to the weights of a dramatically superior mannequin. Thus, I believe a fair statement is "DeepSeek produced a mannequin near the efficiency of US fashions 7-10 months older, for a superb deal less cost (however not anywhere near the ratios folks have instructed)". But we should not hand the Chinese Communist Party technological benefits when we don't should. Given the United States’ comparative advantages in compute access and reducing-edge models, the incoming administration might discover the time to be right to cash in and put AI export globally at the heart of Trump’s tech policy. This new paradigm entails beginning with the unusual kind of pretrained models, after which as a second stage utilizing RL so as to add the reasoning skills.
4x per yr, that implies that within the atypical course of business - in the conventional tendencies of historical value decreases like those that happened in 2023 and 2024 - we’d expect a model 3-4x cheaper than 3.5 Sonnet/GPT-4o round now. Instead, they appear to be they were carefully devised by researchers who understood how a Transformer works and how its varied architectural deficiencies will be addressed. Instead, I'll give attention to whether or not DeepSeek's releases undermine the case for those export control policies on chips. Just a few weeks in the past I made the case for stronger US export controls on chips to China. In truth, I believe they make export control insurance policies even more existentially necessary than they had been every week ago2. Export controls serve a vital objective: maintaining democratic nations on the forefront of AI growth. AIME 2024: DeepSeek V3 scores 39.2, the highest among all models. HumanEval-Mul: DeepSeek V3 scores 82.6, the very best amongst all fashions. Furthermore, we use an open Code LLM (StarCoderBase) with open training knowledge (The Stack), which allows us to decontaminate benchmarks, prepare models without violating licenses, and run experiments that couldn't otherwise be finished.
 In 2024, the thought of utilizing reinforcement studying (RL) to train models to generate chains of thought has turn into a new focus of scaling. HBM built-in with an AI accelerator utilizing CoWoS know-how is as we speak the essential blueprint for all superior AI chips. The sector is consistently arising with concepts, large and small, that make issues simpler or efficient: it may very well be an improvement to the structure of the mannequin (a tweak to the fundamental Transformer structure that every one of today's fashions use) or simply a manner of operating the model extra effectively on the underlying hardware. New generations of hardware even have the same impact. Ultimately, AI companies in the US and different democracies must have better models than those in China if we need to prevail. To be clear, they’re not a option to duck the competition between the US and China. From GPT-four all the way until Claude 3.5 Sonnet we saw the same factor. For instance that is less steep than the unique GPT-4 to Claude 3.5 Sonnet inference value differential (10x), and 3.5 Sonnet is a better model than GPT-4.
In 2024, the thought of utilizing reinforcement studying (RL) to train models to generate chains of thought has turn into a new focus of scaling. HBM built-in with an AI accelerator utilizing CoWoS know-how is as we speak the essential blueprint for all superior AI chips. The sector is consistently arising with concepts, large and small, that make issues simpler or efficient: it may very well be an improvement to the structure of the mannequin (a tweak to the fundamental Transformer structure that every one of today's fashions use) or simply a manner of operating the model extra effectively on the underlying hardware. New generations of hardware even have the same impact. Ultimately, AI companies in the US and different democracies must have better models than those in China if we need to prevail. To be clear, they’re not a option to duck the competition between the US and China. From GPT-four all the way until Claude 3.5 Sonnet we saw the same factor. For instance that is less steep than the unique GPT-4 to Claude 3.5 Sonnet inference value differential (10x), and 3.5 Sonnet is a better model than GPT-4.
- 이전글30 Inspirational Quotes On Situs Gotogel 25.02.28
- 다음글تعرفي على أهم 50 مدرب، ومدربة لياقة بدنية في 2025 25.02.28
댓글목록
등록된 댓글이 없습니다.