



New Step-by-step Roadmap For Deepseek
페이지 정보

본문
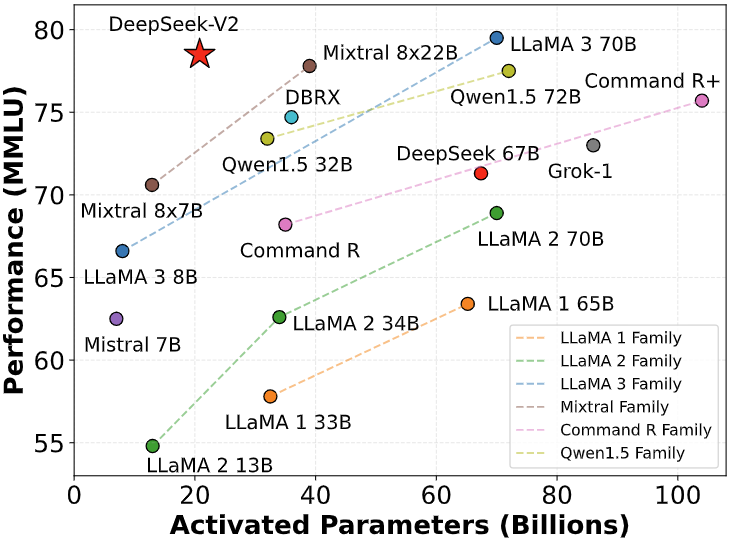 The company launched two variants of it’s DeepSeek Chat this week: a 7B and 67B-parameter DeepSeek LLM, trained on a dataset of two trillion tokens in English and Chinese. At the small scale, we train a baseline MoE model comprising approximately 16B whole parameters on 1.33T tokens. Specifically, block-clever quantization of activation gradients leads to model divergence on an MoE mannequin comprising roughly 16B whole parameters, educated for around 300B tokens. A simple technique is to use block-sensible quantization per 128x128 parts like the way in which we quantize the mannequin weights. Therefore, we conduct an experiment the place all tensors associated with Dgrad are quantized on a block-wise foundation. The results reveal that the Dgrad operation which computes the activation gradients and again-propagates to shallow layers in a sequence-like manner, is very sensitive to precision. We hypothesize that this sensitivity arises as a result of activation gradients are highly imbalanced amongst tokens, resulting in token-correlated outliers (Xi et al., 2023). These outliers can't be effectively managed by a block-sensible quantization strategy. Some are referring to the DeepSeek release as a Sputnik moment for AI in America. Within two weeks of the release of its first Free DeepSeek Ai Chat chatbot app, the cellular app skyrocketed to the top of the app retailer charts in the United States.
The company launched two variants of it’s DeepSeek Chat this week: a 7B and 67B-parameter DeepSeek LLM, trained on a dataset of two trillion tokens in English and Chinese. At the small scale, we train a baseline MoE model comprising approximately 16B whole parameters on 1.33T tokens. Specifically, block-clever quantization of activation gradients leads to model divergence on an MoE mannequin comprising roughly 16B whole parameters, educated for around 300B tokens. A simple technique is to use block-sensible quantization per 128x128 parts like the way in which we quantize the mannequin weights. Therefore, we conduct an experiment the place all tensors associated with Dgrad are quantized on a block-wise foundation. The results reveal that the Dgrad operation which computes the activation gradients and again-propagates to shallow layers in a sequence-like manner, is very sensitive to precision. We hypothesize that this sensitivity arises as a result of activation gradients are highly imbalanced amongst tokens, resulting in token-correlated outliers (Xi et al., 2023). These outliers can't be effectively managed by a block-sensible quantization strategy. Some are referring to the DeepSeek release as a Sputnik moment for AI in America. Within two weeks of the release of its first Free DeepSeek Ai Chat chatbot app, the cellular app skyrocketed to the top of the app retailer charts in the United States.
The data switch occurred every time users accessed the app, potentially exposing sensitive personal information. That stated, DeepSeek's AI assistant reveals its prepare of thought to the person throughout queries, a novel experience for many chatbot users provided that ChatGPT does not externalize its reasoning. Apparently it may even come up with novel ideas for cancer therapy. It will possibly handle complicated queries, summarize content, and even translate languages with high accuracy. Trained on a vast dataset comprising approximately 87% code, 10% English code-related pure language, and 3% Chinese natural language, DeepSeek-Coder undergoes rigorous knowledge high quality filtering to make sure precision and accuracy in its coding capabilities. We validate our FP8 blended precision framework with a comparability to BF16 training on high of two baseline fashions across totally different scales. By intelligently adjusting precision to match the requirements of every process, Free DeepSeek online-V3 reduces GPU reminiscence utilization and hastens coaching, all with out compromising numerical stability and performance. DeepSeek is powered by the open source DeepSeek-V3 mannequin, which its researchers claim was educated for around $6m - significantly lower than the billions spent by rivals.
Llama 2: Open foundation and advantageous-tuned chat fashions. AGIEval: A human-centric benchmark for evaluating foundation models. CLUE: A chinese language language understanding analysis benchmark. Instruction-following evaluation for giant language fashions. At the massive scale, we prepare a baseline MoE mannequin comprising approximately 230B total parameters on round 0.9T tokens. Could You Provide the tokenizer.model File for Model Quantization? Although our tile-smart tremendous-grained quantization effectively mitigates the error launched by function outliers, it requires different groupings for activation quantization, i.e., 1x128 in ahead move and 128x1 for backward cross. Smoothquant: Accurate and environment friendly publish-training quantization for large language fashions. Founded in 2023, DeepSeek began researching and developing new AI instruments - particularly open-source giant language fashions. It affords AI-powered chatbots for customer support, intelligent data analytics instruments for market analysis, and AI automation tools for industries like healthcare, finance, and e-commerce. Developed by a Chinese AI company, DeepSeek has garnered significant consideration for its high-performing models, corresponding to DeepSeek-V2 and DeepSeek-Coder-V2, which consistently outperform business benchmarks and even surpass renowned fashions like GPT-4 and LLaMA3-70B in specific tasks.
Attention is all you want. It has additionally gained the eye of major media shops as a result of it claims to have been skilled at a significantly decrease price of lower than $6 million, compared to $a hundred million for OpenAI's GPT-4. I heard their inferencing framework is way decrease than typical deployment methods. Orca 3/AgentInstruct paper - see the Synthetic Data picks at NeurIPS but this is a superb strategy to get finetue data. However, it isn't exhausting to see the intent behind DeepSeek's rigorously-curated refusals, and as exciting because the open-source nature of DeepSeek is, one should be cognizant that this bias shall be propagated into any future fashions derived from it. For the reason that late 2010s, nevertheless, China’s internet-person progress has plateaued, and key digital services - such as meals delivery, e-commerce, social media, and gaming - have reached saturation. However, unlike lots of its US competitors, DeepSeek is open-supply and Free DeepSeek Ai Chat to make use of. As the hedonic treadmill retains rushing up it’s exhausting to maintain observe, nevertheless it wasn’t that way back that we were upset at the small context home windows that LLMs could take in, or creating small functions to learn our documents iteratively to ask questions, or use odd "prompt-chaining" methods.
- 이전글14 Savvy Ways To Spend Leftover Buying A Driving License Budget 25.02.28
- 다음글15 Best Item Upgrade Bloggers You Must Follow 25.02.28
댓글목록
등록된 댓글이 없습니다.