



Deepseek For Revenue
페이지 정보

본문
 The prices are at present excessive, however organizations like DeepSeek are cutting them down by the day. Forbes reported that Nvidia's market worth "fell by about $590 billion Monday, rose by roughly $260 billion Tuesday and dropped $160 billion Wednesday morning." Other tech giants, like Oracle, Microsoft, Alphabet (Google's mother or father company) and ASML (a Dutch chip equipment maker) also confronted notable losses. The CapEx on the GPUs themselves, no less than for H100s, is probably over $1B (based on a market value of $30K for a single H100). 1.9s. All of this might seem pretty speedy at first, but benchmarking just 75 fashions, with 48 instances and 5 runs every at 12 seconds per task would take us roughly 60 hours - or over 2 days with a single course of on a single host. On the time, they completely used PCIe instead of DGX model of A100, since on the time the models they skilled could match within a single forty GB GPU VRAM, so there was no want for the upper bandwidth of DGX (i.e. they required solely data parallelism but not mannequin parallelism). They later included NVLinks and NCCL, to train bigger fashions that required model parallelism. Is it spectacular that DeepSeek-V3 price half as a lot as Sonnet or 4o to practice?
The prices are at present excessive, however organizations like DeepSeek are cutting them down by the day. Forbes reported that Nvidia's market worth "fell by about $590 billion Monday, rose by roughly $260 billion Tuesday and dropped $160 billion Wednesday morning." Other tech giants, like Oracle, Microsoft, Alphabet (Google's mother or father company) and ASML (a Dutch chip equipment maker) also confronted notable losses. The CapEx on the GPUs themselves, no less than for H100s, is probably over $1B (based on a market value of $30K for a single H100). 1.9s. All of this might seem pretty speedy at first, but benchmarking just 75 fashions, with 48 instances and 5 runs every at 12 seconds per task would take us roughly 60 hours - or over 2 days with a single course of on a single host. On the time, they completely used PCIe instead of DGX model of A100, since on the time the models they skilled could match within a single forty GB GPU VRAM, so there was no want for the upper bandwidth of DGX (i.e. they required solely data parallelism but not mannequin parallelism). They later included NVLinks and NCCL, to train bigger fashions that required model parallelism. Is it spectacular that DeepSeek-V3 price half as a lot as Sonnet or 4o to practice?
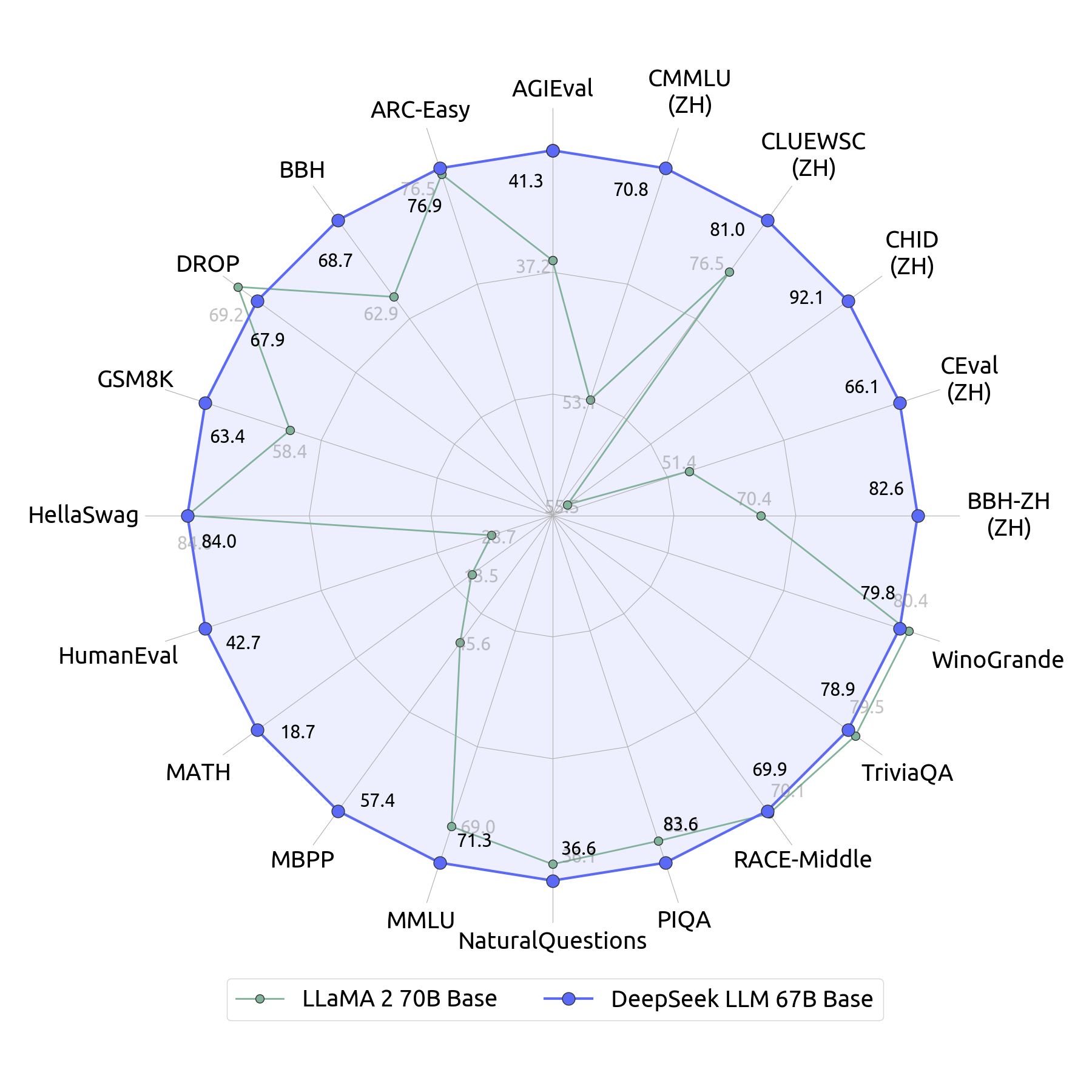 Its coaching supposedly costs lower than $6 million - a shockingly low determine when compared to the reported $a hundred million spent to practice ChatGPT's 4o model. Note: The entire measurement of DeepSeek-V3 models on HuggingFace is 685B, which incorporates 671B of the principle Model weights and 14B of the Multi-Token Prediction (MTP) Module weights. It’s their latest mixture of experts (MoE) mannequin educated on 14.8T tokens with 671B complete and 37B lively parameters. At an economical price of only 2.664M H800 GPU hours, we full the pre-coaching of DeepSeek-V3 on 14.8T tokens, producing the at present strongest open-supply base model. Meanwhile, we also maintain a control over the output type and length of DeepSeek-V3. This extends the context size from 4K to 16K. This produced the bottom models. To assist the analysis neighborhood, we now have open-sourced DeepSeek-R1-Zero, DeepSeek-R1, and six dense fashions distilled from DeepSeek-R1 primarily based on Llama and Qwen. DeepSeek AI has open-sourced each these models, permitting companies to leverage beneath particular terms. It was so good that Deepseek folks made a in-browser atmosphere too.
Its coaching supposedly costs lower than $6 million - a shockingly low determine when compared to the reported $a hundred million spent to practice ChatGPT's 4o model. Note: The entire measurement of DeepSeek-V3 models on HuggingFace is 685B, which incorporates 671B of the principle Model weights and 14B of the Multi-Token Prediction (MTP) Module weights. It’s their latest mixture of experts (MoE) mannequin educated on 14.8T tokens with 671B complete and 37B lively parameters. At an economical price of only 2.664M H800 GPU hours, we full the pre-coaching of DeepSeek-V3 on 14.8T tokens, producing the at present strongest open-supply base model. Meanwhile, we also maintain a control over the output type and length of DeepSeek-V3. This extends the context size from 4K to 16K. This produced the bottom models. To assist the analysis neighborhood, we now have open-sourced DeepSeek-R1-Zero, DeepSeek-R1, and six dense fashions distilled from DeepSeek-R1 primarily based on Llama and Qwen. DeepSeek AI has open-sourced each these models, permitting companies to leverage beneath particular terms. It was so good that Deepseek folks made a in-browser atmosphere too.
I frankly don't get why folks have been even utilizing GPT4o for code, I had realised in first 2-three days of utilization that it sucked for even mildly advanced tasks and i caught to GPT-4/Opus. Models ought to earn factors even if they don’t handle to get full coverage on an example. Still, there is a strong social, economic, and authorized incentive to get this right-and the technology business has gotten a lot better over the years at technical transitions of this form. He was not too long ago seen at a gathering hosted by China's premier Li Qiang, reflecting DeepSeek's rising prominence within the AI trade. You possibly can basically write code and render the program in the UI itself. Let’s take a look at an example with the exact code for Go and Java. "You have to first write a step-by-step outline and then write the code. Social media networks and different media viewing software program would want to construct new user interfaces to offer customers visibility into all this new information. It goals to be backwards appropriate with present cameras and media editing workflows whereas additionally engaged on future cameras with dedicated hardware to assign the cryptographic metadata.
While it's tempting to attempt to resolve this drawback across all of social media and journalism, this can be a diffuse challenge. In standard MoE, some experts can grow to be overused, while others are rarely used, losing area. The usual does not require tracking the entire history of alterations and sources, leaving gaps in provenance. However, to make faster progress for this version, we opted to use customary tooling (Maven and OpenClover for Java, gotestsum for Go, and Symflower for consistent tooling and output), which we can then swap for better solutions in the approaching versions. However, this iteration already revealed a number of hurdles, insights and doable improvements. 3. When evaluating mannequin performance, it is strongly recommended to conduct multiple checks and average the results. Then I realised it was exhibiting "Sonnet 3.5 - Our most clever model" and it was seriously a major shock. I feel I love sonnet. The take a look at exited the program. Claude actually reacts properly to "make it higher," which seems to work without limit till eventually this system gets too large and Claude refuses to finish it.
When you have virtually any inquiries with regards to in which as well as how you can employ شات ديب سيك, it is possible to e-mail us on our web site.
- 이전글Car Keys Programmed Tools To Make Your Daily Life Car Keys Programmed Trick That Everyone Should Learn 25.02.10
- 다음글10 Audi A1 Key Replacement Tricks Experts Recommend 25.02.10
댓글목록
등록된 댓글이 없습니다.